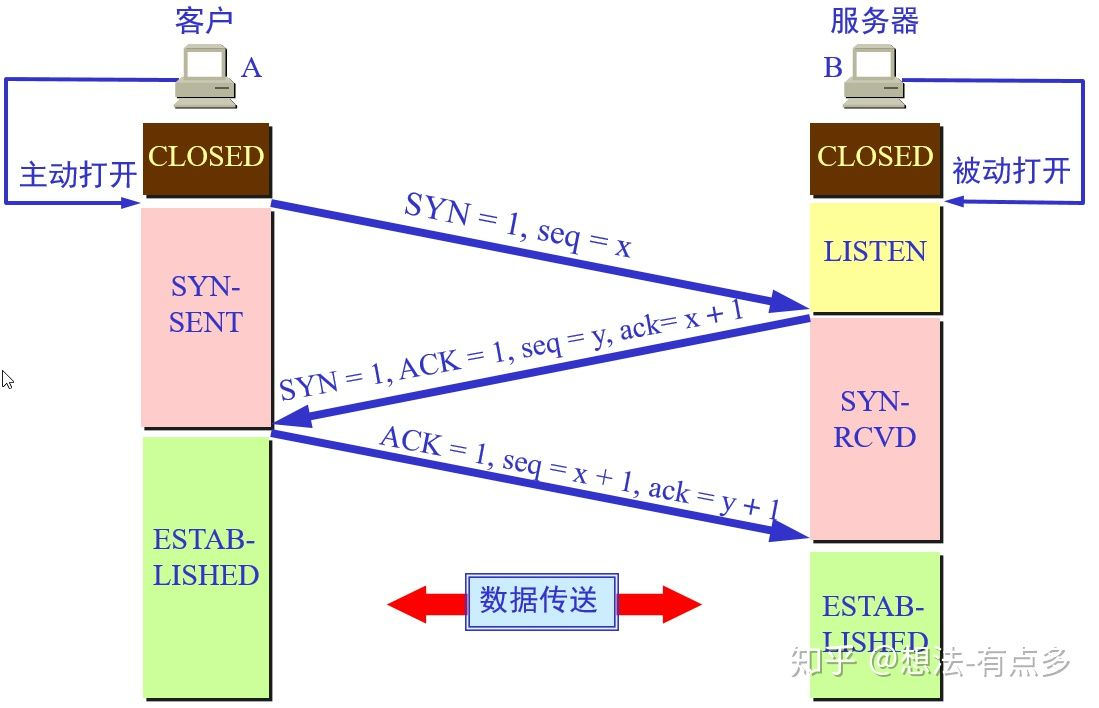
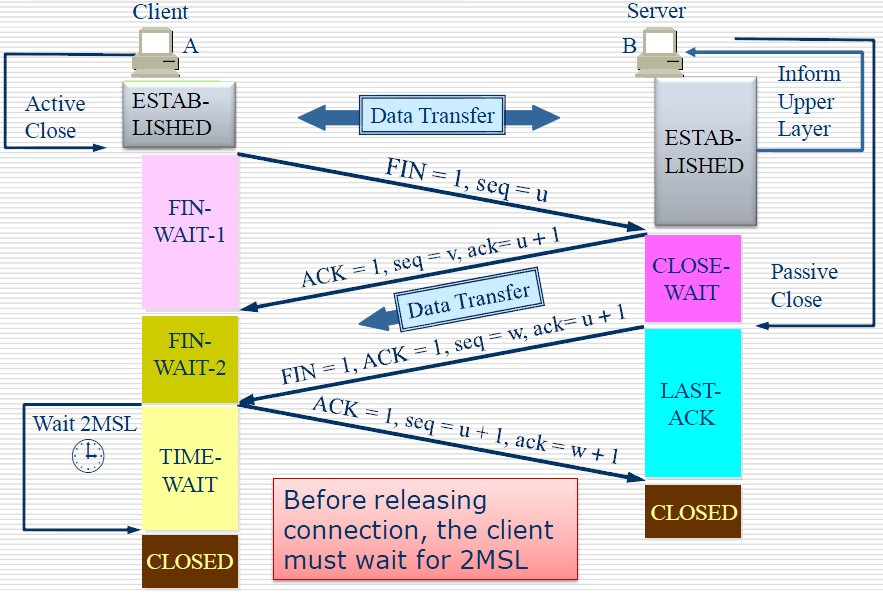
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
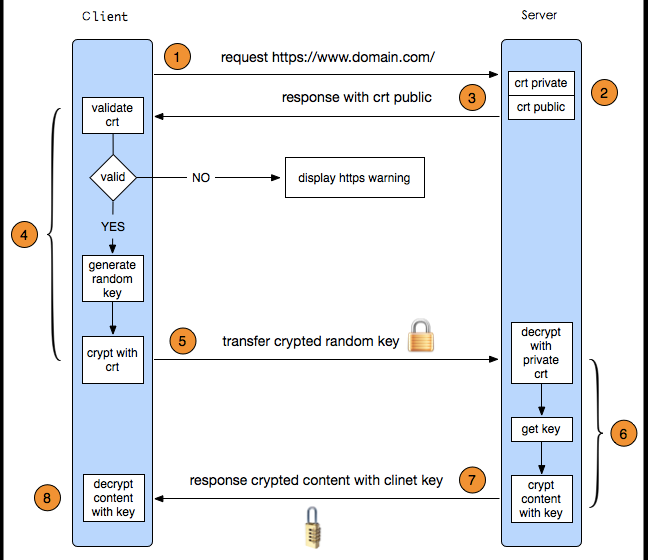
| 一个HTTPS请求实际上包含了两次HTTP传输,可以细分为8步。
1.客户端向服务器发起HTTPS请求,连接到服务器的443端口
2.服务器端有一个密钥对,即公钥和私钥,是用来进行非对称加密使用的,服务器端保存着私钥,不能将其泄露,公钥可以发送给任何人。
3.服务器将自己的公钥发送给客户端。
4.客户端收到服务器端的公钥之后,会对公钥进行检查,验证其合法性,如果发现发现公钥有问题,那么HTTPS传输就无法继续。严格的说,这里应该是验证服务器发送的数字证书的合法性,关于客户端如何验证数字证书的合法性,下文会进行说明。如果公钥合格,那么客户端会生成一个随机值,这个随机值就是用于进行对称加密的密钥,我们将该密钥称之为client key,即客户端密钥,这样在概念上和服务器端的密钥容易进行区分。然后用服务器的公钥对客户端密钥进行非对称加密,这样客户端密钥就变成密文了,至此,HTTPS中的第一次HTTP请求结束。
5.客户端会发起HTTPS中的第二个HTTP请求,将加密之后的客户端密钥发送给服务器。
6.服务器接收到客户端发来的密文之后,会用自己的私钥对其进行非对称解密,解密之后的明文就是客户端密钥,然后用客户端密钥对数据进行对称加密,这样数据就变成了密文。
7.然后服务器将加密后的密文发送给客户端。
8.客户端收到服务器发送来的密文,用客户端密钥对其进行对称解密,得到服务器发送的数据。这样HTTPS中的第二个HTTP请求结束,整个HTTPS传输完成。
|