Elasticsearch是什么?
Elasticsearch简称ES,是一个基于Lucene构建的开源、分布式、Restful接口的全文搜索引擎,还是一个分布式文档数据库。天生就是分布式、高可用、可扩展的,可以在很短的时间内存储、搜索和分析大量的数据。
什么是全文搜索?
全文搜索也叫全文检索,是指扫描文章中的每一个词,对每一个词进建立一个索引,指明该词在文章中出现的次数和位置,当前端用户输入的关键词发起查询请求后,搜索引擎就会根据事先建立的索引进行查找,并将查询的结果响应给用户。
这里有两个关键字:分词和索引,Elasticsearch内部会完成这两件事情,对保存的文本内容按规则进行分词,并对这些分词后的词条建立索引,供用户查询。
什么是倒排索引?
全文搜索过程根据关键词创建的索引叫倒排索引,顾名思义,建立正向关系“文本内容-关键词”叫正排索引,后续会介绍,倒排索引就是把原有关系倒过来,建立成“关键词-文本内容”的关系,这样的关系非常利于搜索。
Elasticsearch什么场景适用?
常见场景
搜索类场景
常见的搜索场景比如说电商网站、招聘网站、新闻资讯类网站、各种app内的搜索。
日志分析类场景
经典的ELK组合(Elasticsearch/Logstash/Kibana),可以完成日志收集,日志存储,日志分析查询界面基本功能,目前该方案的实现很普及,大部分企业日志分析系统都是使用该方案。
数据预警平台及数据分析场景
例如电商价格预警,在支持的电商平台设置价格预警,当优惠的价格低于某个值时,触发通知消息,通知用户购买。
数据分析常见的比如分析电商平台销售量top 10的品牌,分析博客系统、头条网站top 10关注度、评论数、访问量的内容等等。
商业BI系统
比大型零售超市,需要分析上一季度用户消费金额,年龄段,每天各时间段到店人数分布等信息,输出相应的报表数据,并预测下一季度的热卖商品,根据年龄段定向推荐适宜产品。Elasticsearch执行数据分析和挖掘,Kibana做数据可视化。
常见案例
- 维基百科、百度百科:有全文检索、高亮、搜索推荐功能
- stack overflow:有全文检索,可以根据报错关键信息,去搜索解决方法。
- github:从上千亿行代码中搜索你想要的关键代码。
- 日志分析系统:各企业内部搭建的ELK平台
Elasticsearch的架构图
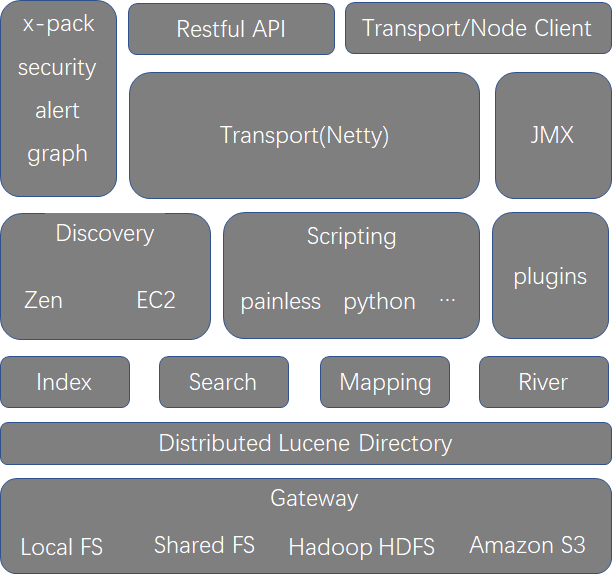
架构各组件简单释义:
- gateway 底层存储系统,一般为文件系统,支持多种类型。
- distributed lucence directory 基于lucence的分布式框架,封装了建立倒排索引、数据存储、translog、segment等实现。
- 模块层 ES的主要模块,包含索引模块、搜索模块、映射模块。
- Discovery 集群node发现模块,用于集群node之间的通信,选举coordinate node操作,支持多种发现机制,如zen,ec2等。
- script 脚本解析模块,用来支持在查询语句中编写的脚本,如painless,groovy,python等。
- plugins 第三方插件,各种高级功能可由插件提供,支持定制。
- transport/jmx 通信模块,数据传输,底层使用netty框架
- restful/node 对外提供的访问Elasticsearch集群的接口
- x-pack elasticsearch的一个扩展包,集成安全、警告、监视、图形和报告功能,无缝接入,可插拔设计。
基本概念
NRT
Near Realtime,近实时,有两个层面的含义,一是从写入一条数据到这条数据可以被搜索,有一段非常小的延迟(大约1秒左右),二是基于Elasticsearch的搜索和分析操作,耗时可以达到秒级。
Cluster
集群,对外提供索引和搜索的服务,包含一个或多个节点,每个节点属于哪个集群是通过集群名称来决定的(默认名称是elasticsearch),集群名称搞错了后果很严重。命名建议是研发、测试环境、准生产、生产环境用不同的名称增加区分度,例如研发使用es-dev,测试使用es-test,准生产使用es-stg,生产环境使用es-pro这样的名字来区分。如果是中小型应用,集群可以只有一个节点。
Node
单独一个Elasticsearch服务器实例称为一个node,node是集群的一部分,每个node有独立的名称,默认是启动时获取一个UUID作为名称,也可以自行配置,node名称特别重要,Elasticsearch集群是通过node名称进行管理和通信的,一个node只能加入一个Elasticsearch集群当中,集群提供完整的数据存储,索引和搜索的功能,它下面的每个node分摊上述功能(每条数据都会索引到node上)。
shard
分片,是单个Lucene索引,由于单台机器的存储容量是有限的(如1TB),而Elasticsearch索引的数据可能特别大(PB级别,并且30GB/天的写入量),单台机器无法存储全部数据,就需要将索引中的数据切分为多个shard,分布在多台服务器上存储。利用shard可以很好地进行横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升集群整体的吞吐量和性能。
shard在使用时比较简单,只需要在创建索引时指定shard的数量即可,剩下的都交给Elasticsearch来完成,只是创建索引时一旦指定shard数量,后期就不能再更改了。
replica
索引副本,完全拷贝shard的内容,shard与replica的关系可以是一对多,同一个shard可以有一个或多个replica,并且同一个shard下的replica数据完全一样,replica作为shard的数据拷贝,承担以下三个任务:
- shard故障或宕机时,其中一个replica可以升级成shard。
- replica保证数据不丢失(冗余机制),保证高可用。
- replica可以分担搜索请求,提升整个集群的吞吐量和性能。
shard的全称叫primary shard,replica全称叫replica shard,primary shard数量在创建索引时指定,后期不能修改,replica shard后期可以修改。默认每个索引的primary shard值为5,replica shard值为5,含义是5个primary shard,5个replica shard,共10个shard。
Index
索引,具有相同结构的文档集合,类似于关系型数据库的数据库实例(6.0.0版本type废弃后,索引的概念下降到等同于数据库表的级别)。一个集群里可以定义多个索引,如客户信息索引、商品分类索引、商品索引、订单索引、评论索引等等,分别定义自己的数据结构。
索引命名要求全部使用小写,建立索引、搜索、更新、删除操作都需要用到索引名称。
type
类型,原本是在索引(Index)内进行的逻辑细分,但后来发现企业研发为了增强可阅读性和可维护性,制订的规范约束,同一个索引下很少还会再使用type进行逻辑拆分(如同一个索引下既有订单数据,又有评论数据),因而在6.0.0版本之后,此定义废弃。
Document
文档,Elasticsearch最小的数据存储单元,JSON数据格式,类似于关系型数据库的表记录(一行数据),结构定义多样化,同一个索引下的document,结构尽可能相同。
工作原理
启动过程
当Elasticsearch的node启动时,默认使用广播寻找集群中的其他node,并与之建立连接,如果集群已经存在,其中一个节点角色特殊一些,叫coordinate node(协调者,也叫master节点),负责管理集群node的状态,有新的node加入时,会更新集群拓扑信息。如果当前集群不存在,那么启动的node就自己成为coordinate node。
应用程序与集群通信过程
虽然Elasticsearch设置了Coordinate Node用来管理集群,但这种设置对客户端(应用程序)来说是透明的,客户端可以请求任何一个它已知的node,如果该node是集群当前的Coordinate,那么它会将请求转发到相应的Node上进行处理,如果该node不是Coordinate,那么该node会先将请求转交给Coordinate Node,再由Coordinate进行转发,搓着各node返回的数据全部交由Coordinate Node进行汇总,最后返回给客户端。
集群内node有效性检测
正常工作时,Coordinate Node会定期与拓扑结构中的Node进行通信,检测实例是否正常工作,如果在指定的时间周期内,Node无响应,那么集群会认为该Node已经宕机。集群会重新进行均衡:
- 重新分配宕机的Node,其他Node中有该Node的replica shard,选出一个replica shard,升级成为primary shard。
- 重新安置新的shard。
- 拓扑更新,分发给该Node的请求重新映射到目前正常的Node上。
Restful API
Kibana界面的Dev Tools菜单,可以发送Elasticsearch的Restful请求。
检查集群的健康状况
1 | GET /_cat/health?v |
1 | epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent |
集群的状态有green、yellow、red三种,定义如下:
- green:每个索引的primary shard和replica shard都是active状态的
- yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
- red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
查看集群索引
1 | GET /_cat/indices?v |
1 | health status index pri rep docs.count docs.deleted store.size pri.store.size |
查看node信息
1 | GET /_cat/nodes?v |
1 | host ip heap.percent ram.percent load node.role master name |
创建索引命令
1 | PUT /test?pretty |
1 | { |
删除索引命令
1 | DELETE /test?pretty |
1 | { |